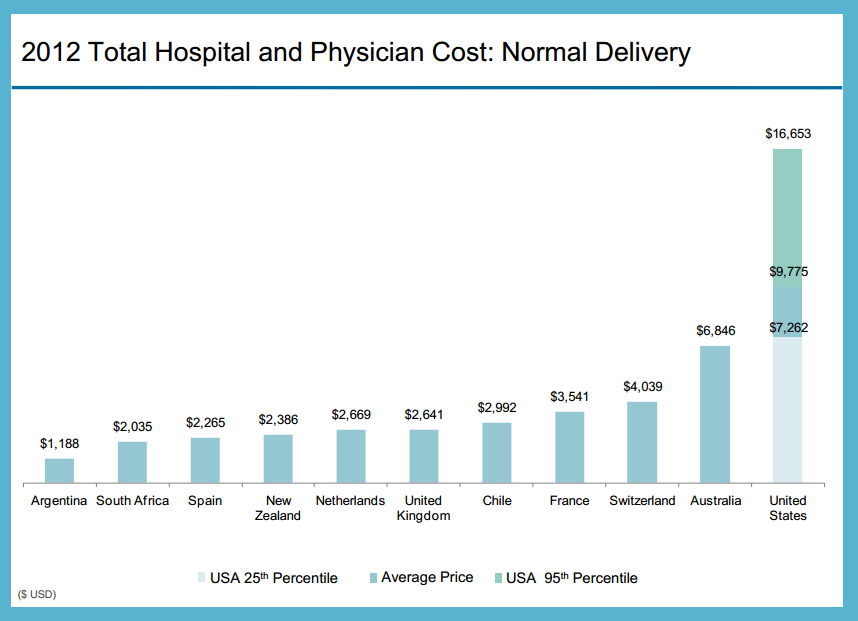
An interesting observation – unintended consequence of non-universal healthcare?: As consumers are being asked to pay more, so they’re trying to become better health-care shoppers.
- states have passed transparency laws
- medicare has started to dump raw service cost data
- private firms are developing their own transparency tools
- a report recommends:
- total estimated price
- out-of-pocket costs
- patient safety and clinical outcome data
“Care providers, employers and health plans have negotiated rates, which isn’t necessarily something they want out in the public. They warn making those negotiations publicly could actually discourage negotiations for lower prices — naturally, there are conflicting opinions on this point.”
http://www.washingtonpost.com/blogs/wonkblog/wp/2014/04/16/price-transparency-stinks-in-health-care-heres-how-the-industry-wants-to-change-that/
![]()
Price transparency stinks in health care. Here’s how the industry wants to change that.
By Jason Millman
There’s been much written in the past year about just how hard it is to get a simple price for a basic health-care procedure. The industry has heard the rumblings, and now it’s responding.
About two dozen industry stakeholders, including main lobbying groups for hospitals and health insurers, this morning are issuing new recommendations for how they can provide the cost of health-care services to patients.
The focus on health-care price transparency — discussed in Steven Brill’s 26,000-word opus on medical bills for Time last year — has intensified, not surprisingly, as people are picking up more of the tab for their health care. Employers are shifting more costs onto their workers, and many new health plans under Obamacare feature high out-of-pocket costs.
The health care-industry has some serious catching up to do on the transparency front. States have passed their own health price transparency laws, Medicare has started to dump raw data on the cost of services and what doctors get paid, and private firms have developed their own transparency tools.
“We need to own this as an industry. We need to step up,” said Joseph Fifer, president and CEO of the Healthcare Financial Management Association, who coordinated the group issuing the report this morning. The stakeholder group includes hospitals, consumer advocates, doctors and health systems.
Their recommendations delineate who in the health-care system should be responsible for providing pricing information and what kind of information to provide depending on a person’s insurance status. Just getting the different stakeholders on the same page was difficult enough in the past, said Rich Umbdenstock, president and CEO of the American Hospital Association.
“We couldn’t agree on whose role was what. We were using terms differently,” he said.
The report’s major recommendations include how to provide patients with:
- the total estimated price of the service
- a clear indication of whether the provider is in-network or where to find an in-network provider
- a patient’s out-of-pocket costs
- and other relevant information, like patient safety scores and clinical outcomes.
“I think that the focus now, unlike three years ago when it was on access, the focus is about affordability,” said Karen Ignagni, president and CEO of America’s Health Insurance Plans. “What are the prices being charged? It leads consumers to want to know, ‘How do I evaluate all that?'”
To give a sense of just how murky health pricing can be, one of the group’s recommendations is for providers to offer uninsured patients their estimated cost for a standard procedure and to make clear how complications could increase the price. You would think that shouldn’t be too hard — there’s no insurer to deal with, no contracts to consult.
But previous research points out just how difficult it can be to get the price for a basic, uncomplicated procedure. In a study published this past December, researchers found that just three out of 20 hospitals could say how much an uninsured person should expect to pay for a simple test measuring heartbeat rate.
The group’s recommendations also touches on limits to transparency and the “unintended consequences” of too much data being public. Care providers, employers and health plans have negotiated rates, which isn’t necessarily something they want out in the public. They warn making those negotiations publicly could actually discourage negotiations for lower prices — naturally, there are conflicting opinions on this point.
The report nods to other ways at achieving transparency. For example, it talks about “reference pricing” in self-funded employer health plans, in which employers limit what they’ll pay for an employee’s health-care services — thus setting the reference price.
“The employer communicates to employees a list of the providers who have agreed to accept the reference price (or less) for their services. If an employee chooses a provider who has not accepted the reference price, the employee is responsible for the amount the provider charges above the reference price,” the report reads, noting that Safeway grocery stores implemented a successful pilot program that expanded a few years ago.
Perhaps what’s most significant about these recommendations is the stakeholders’ acknowledgement that the health-care market is changing. Consumers are being asked to pay more, so they’re trying to become better health-care shoppers
AHIP’s Ignagni said most insurers already provide cost calculator tools and quality data on their Web sites. Providers, said the AHA’s Umbdenstock, need to be more accommodating to patients’ price-sensitivity.
“‘We can’t answer your question’ may have worked in the past, but it doesn’t fly any longer,” said Mark Rukavina, principal with Community Health Advisors and a report contributor. “This [report] basically lays out the principles for creating a new response to the question.”
Jason Millman covers all things health policy, with a focus on Obamacare implementation. He previously covered health policy for Politico. He is an unapologetic fan of the New York Yankees and Giants, though the Nationals and Teddy Roosevelt hold a small place in his heart. He’s on Twitter.